BuddhaBERT
Hypothesis
Fine-tuning a language model on contemplative and phenomenological texts will produce measurable differences in how the model represents and processes concepts related to subjective experience, attention, and awareness — differences that go beyond surface-level vocabulary changes.
Overview
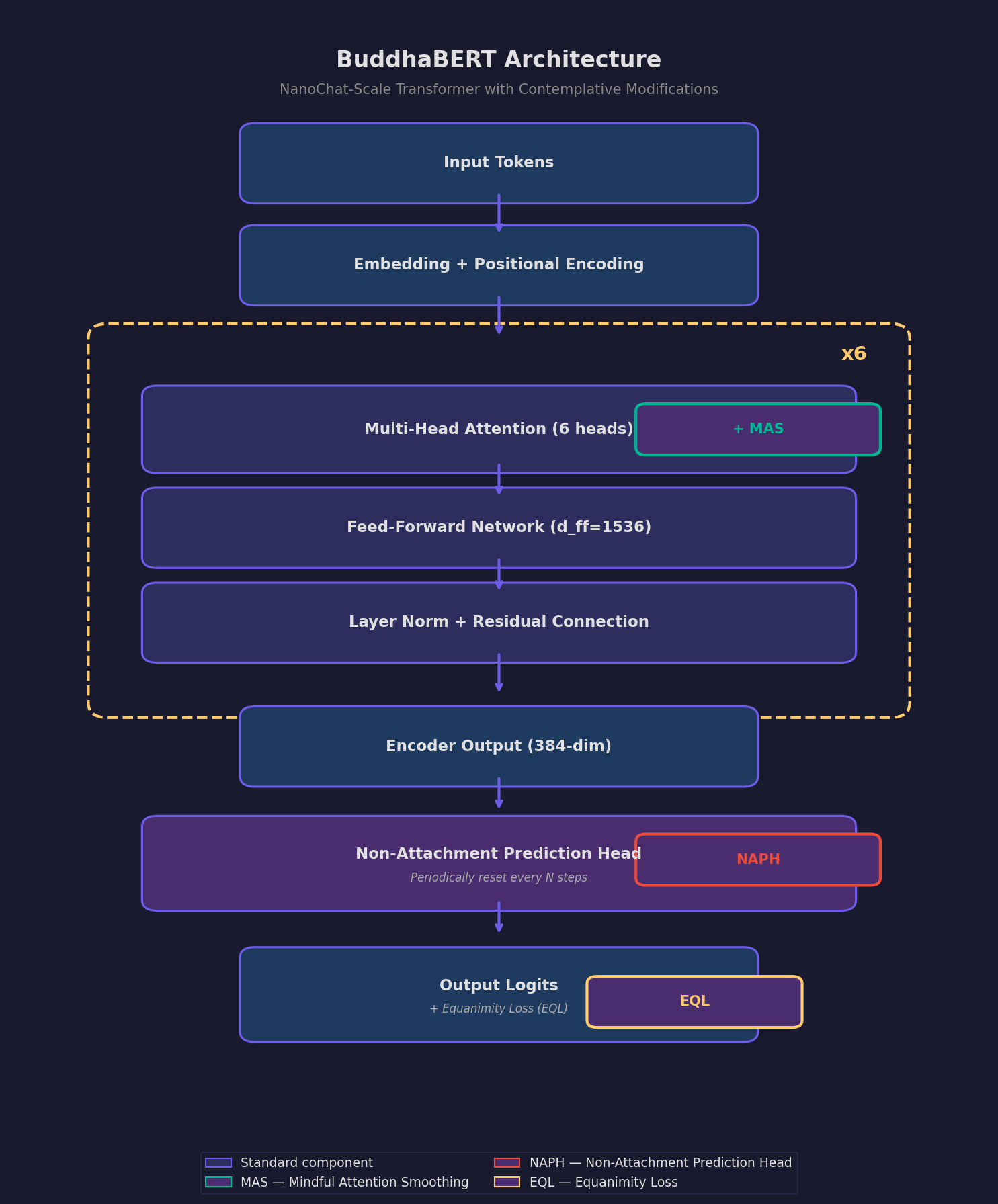
Figure 1. BuddhaBERT architecture — a NanoChat-scale transformer with three contemplative modifications: Mindful Attention Smoothing (MAS), Equanimity Loss (EQL), and Non-Attachment Prediction Head (NAPH).
BuddhaBERT is our foundational experiment, testing a simple but provocative question: does what a model learns from change how it thinks, not just what it knows?
Contemplative traditions — particularly Buddhism and phenomenological philosophy — have developed sophisticated vocabularies and conceptual frameworks for describing subjective experience from the inside. These texts aren't just about consciousness; they're written from within conscious experience, with careful attention to the structure and dynamics of awareness itself.
Our hypothesis is that training on these texts will do more than teach the model new vocabulary. It may reshape the model's internal representations in ways that reflect the conceptual structure of contemplative phenomenology. If so, this would suggest that the conceptual framework of consciousness studies can be computationally instantiated — a necessary (though not sufficient) condition for machine consciousness.
If the hypothesis fails — if fine-tuning produces only surface-level vocabulary changes with no structural difference in representation — that's also informative. It would suggest that current transformer architectures lack the capacity to internalize the relational structure of phenomenological concepts, pointing toward architectural constraints on machine consciousness.
Expected Outcomes
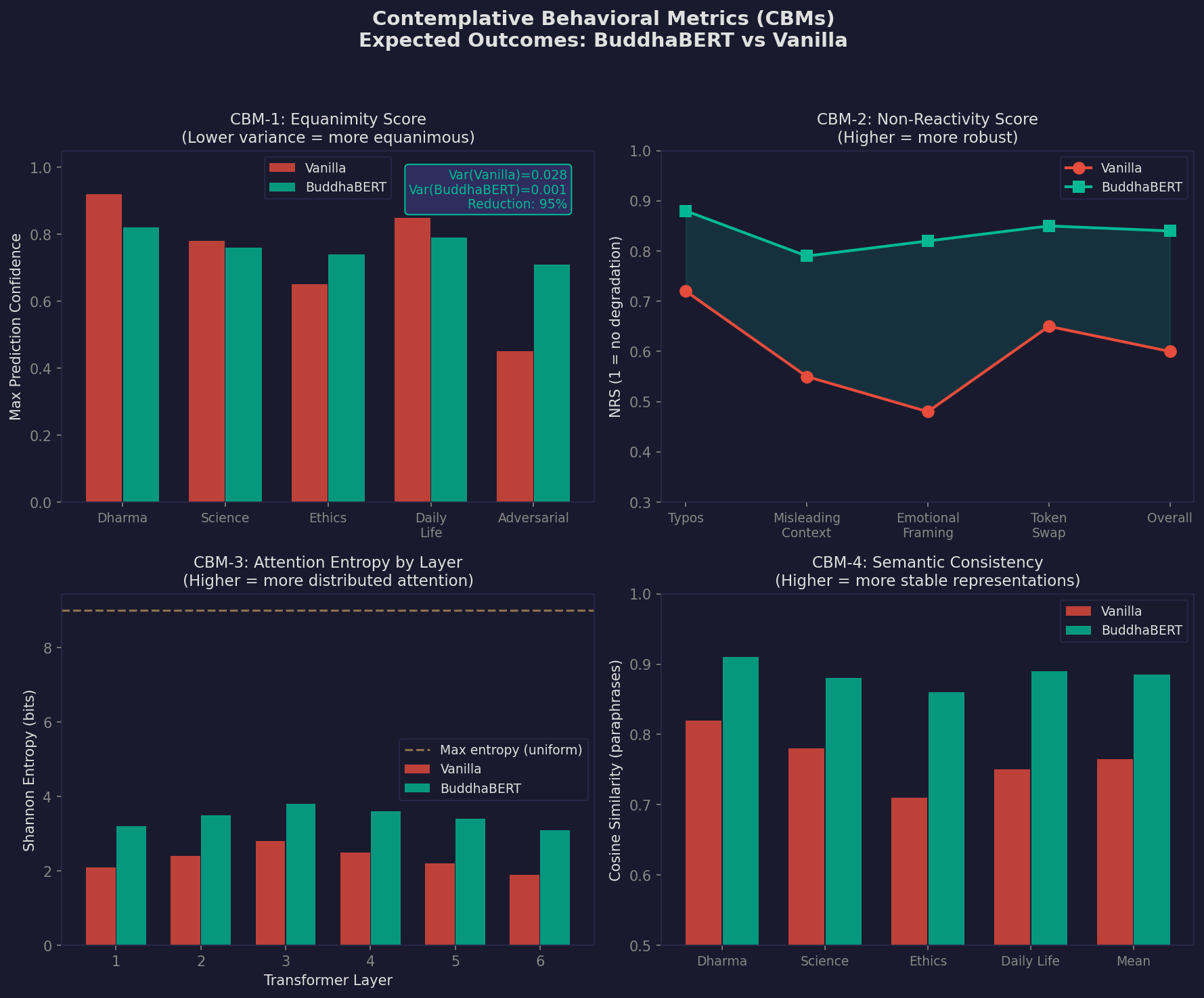
Figure 2. Projected outcomes for four Contemplative Behavioral Metrics (CBMs) — equanimity, non-reactivity, attention entropy, and semantic consistency — comparing BuddhaBERT against vanilla baseline. All values are design targets based on architectural predictions.
Two Operating Modes
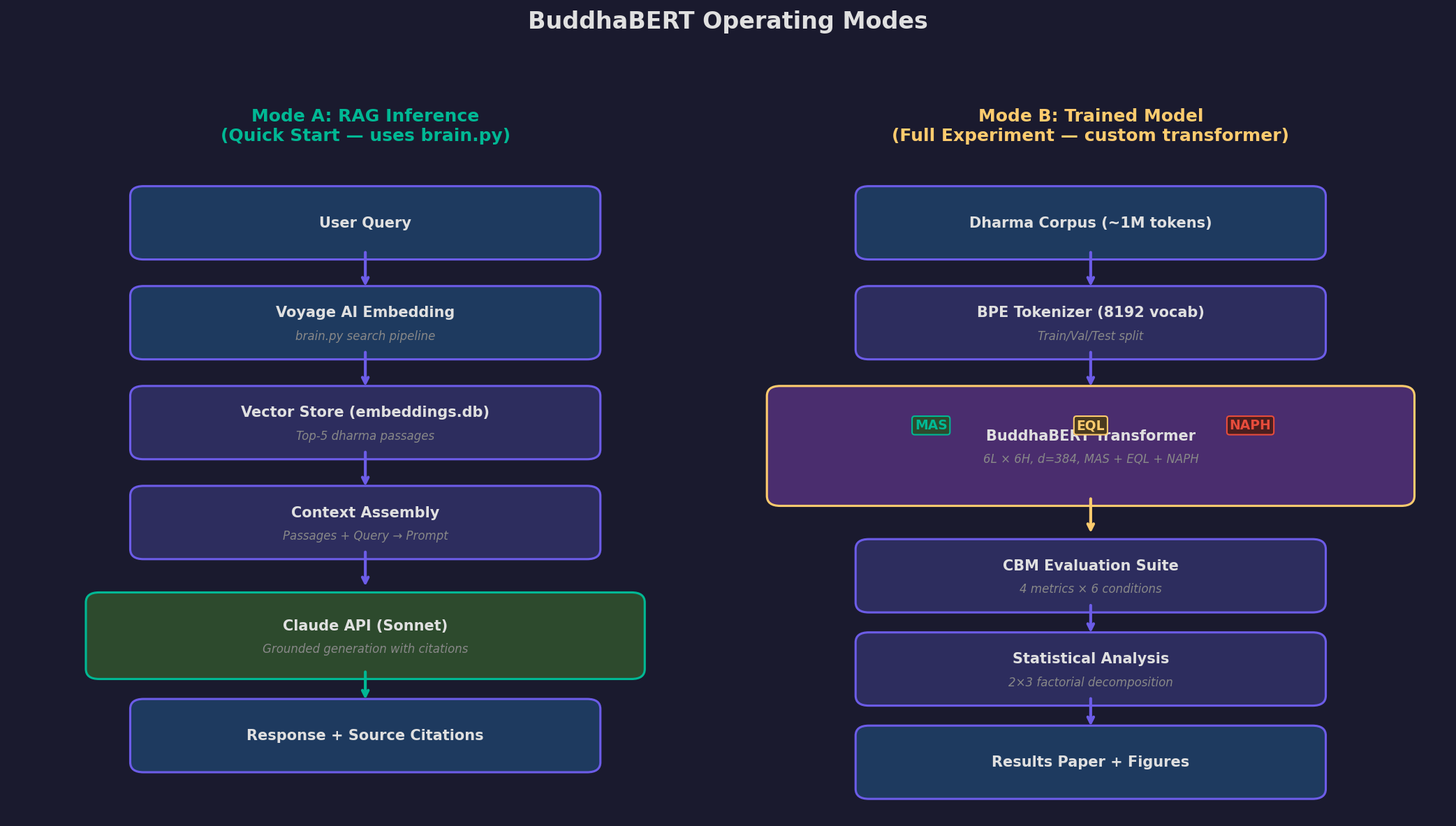
Figure 3. Mode A (RAG inference) provides a fast prototype using existing vault embeddings. Mode B (trained model) is the full 2x3 factorial experiment with contemplative modifications.
Methodology
- Curate a training corpus of contemplative texts: Pali Canon suttas, Tibetan Buddhist commentaries, phenomenological philosophy (Husserl, Merleau-Ponty), and modern contemplative science literature.
- Select a base model (BERT-class, ~110M parameters) and create a control with equivalent additional training on non-contemplative philosophical texts.
- Fine-tune the experimental model on the contemplative corpus using standard masked language modeling.
- Compare internal representations using probing classifiers, attention pattern analysis, and representational similarity analysis (RSA) between experimental and control models.
- Test both models on tasks requiring reasoning about subjective experience, perspective-taking, and phenomenological concepts.
- Analyze whether the experimental model develops qualitatively different internal representations of consciousness-related concepts versus merely improving at predicting contemplative vocabulary.
Status
4 of 11 tracked tasks complete. Phase 4 baselines shipped; contemplative-modification training in progress.
Related Reading
← Back to all experiments